
注明:因为这部分内容涉及到工作,所以笔者会将真实的业务逻辑隐藏,呈现的例子不具有很强的业务性,如果数据场景不恰当还请见谅,就当一个解决方案看一下就好。
原因
众所周知hbase是k-v 数据库,它只能通过key直接获取数据(get,scan),不能够实现类似于mysql组合索引方式的查询。因为这个原因一般在hbase key的设计中,会按照业务查询逻辑进行组合,但无论如何组合运用在很多场景中很不适用,不管运用协处理器还是正则匹配key效率都会非常的查。因此我们才行到运用solr建立索引,通过lily hbase index 做为中间件将需要索引的hbase列同步至solr,从而实现hbase的二级索引(组合索引)
实现思路
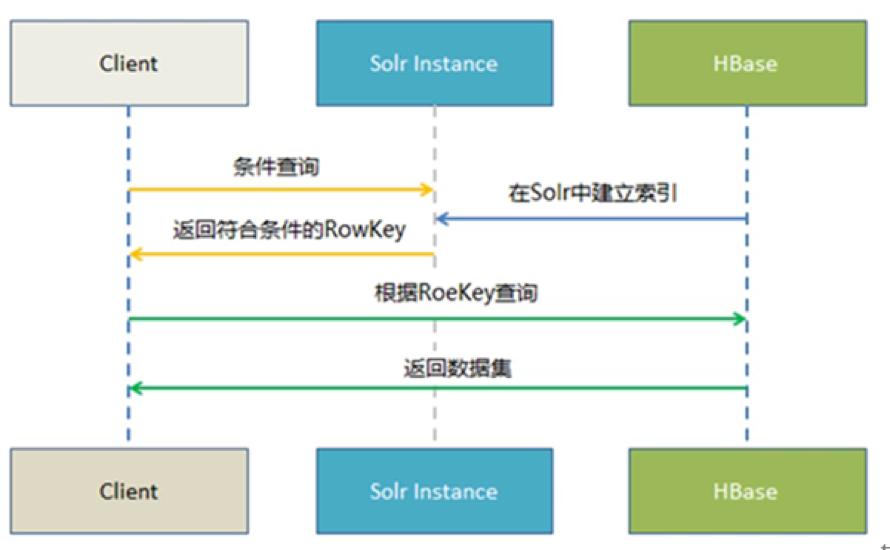
(1) 在hbase中插入数据,通过 lily hbase index 自动叫需要索引的列同步至solr 中建立索引。(蓝色线)
(2) 客户端(client)带入查询条件到 solr 索引集合,solr 找到符合条件的hbase key 返回给客户端。(黄色线)
(3) 客户端(client) 根据返回的rowkey 查询hbase,返回查询到的结果。(绿色线)
实现样例
上篇我们配置了lily hbase index,这篇我们继续运用上篇的配置信息。完成插入和查询的演示。
hbase 数据录入
首先我们需要一份测试数据,并将数据录入到hbase中,录入的时候就会触发 lily 的Event事件,将数据索引信息同步至solr中。
(1) 样例文件
我们有一份student.txt 文件存放于hdfs上,文件以tab符分割,顺序分别为[学生编号,姓名,性别,年龄,住址]
1 | 000001 wxx man 18 河北省廊坊市固安县 |
(2) MR方式同步文件至hbase
本来直接调用hbase api就能够实现,而且非常简单,但我就是想往复杂了写。
1 | public class StudentHbaseTool { |
运行命令,hadoop -jar student-hbase-toole.jar hdfs://xxxx:xxx/xxx/student.txt 将文件录入至 basic_data:user_info 表中,key是学生编号,列全部存入data列族下。
solr 数据查询
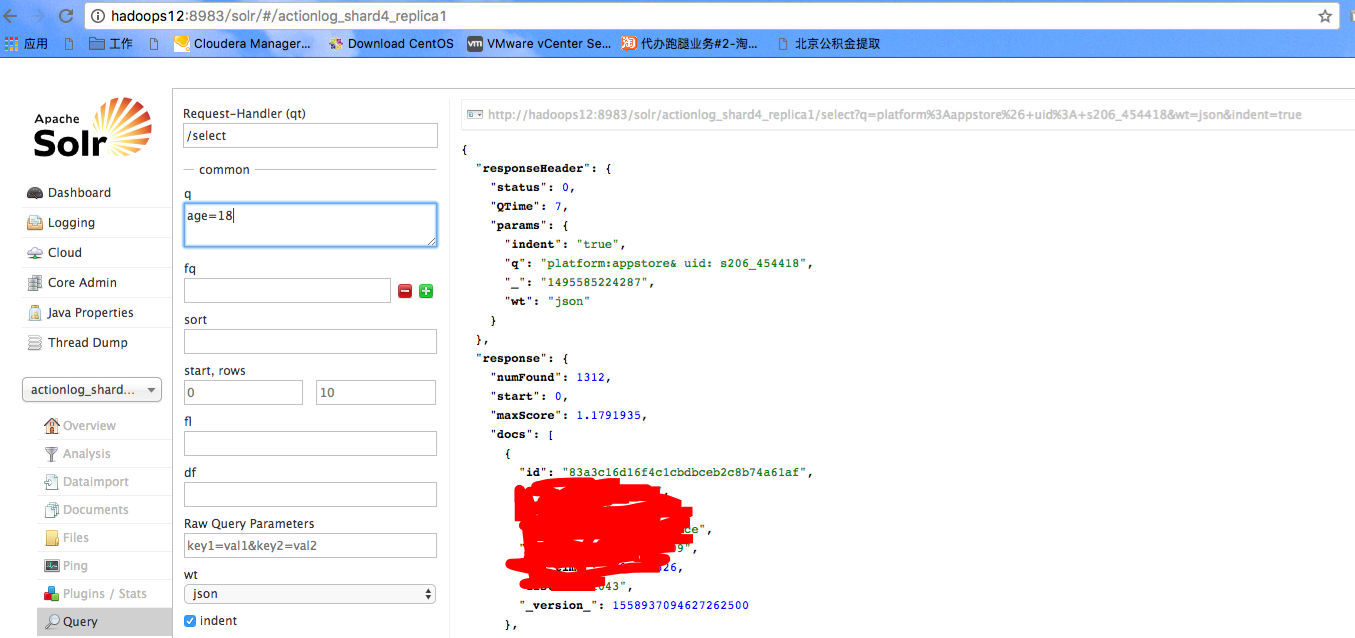
(1) 我们打开solr web页面,点击query页进行查询(基本的solr语法我们就不做说明了,有时间单独写一篇介绍) 在 q 这个文本框内输入条件 age=18,搜索出符合条件的数据索引,拿到id列(hbase 的key)。
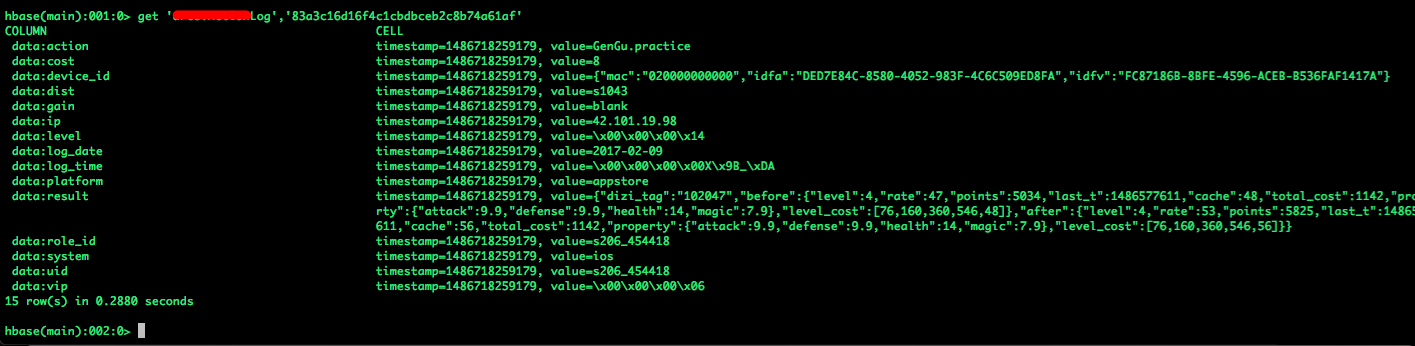
(2) 通过 hbase shell 进行数据查询,并执行命令
1 | get "basic_data:user_info" "000001" |
说明:后面的查询步骤是可以通过api实现自动化的,需要自己封装,有时间的话会写一个事例上去给大家作参考。因为没有真实的环境,后面两张配图和事例中的业务有一些出入,希望大家可以见谅。下一次有时间我们详细说一下solr这个框架,或者说一下hbase的设计。